
Part 12 of experiments in FreeBSD and Kubernetes: Completing and testing the Kubernetes Cluster
Table of Contents
- Larger Size
- Space
- Bootstrapping the Kubernetes Worker Nodes
- Configuring kubectl for Remote Access
- Provisioning Pod Network Routes
- Deploying the DNS Cluster Add-on
- Smoke Test
- Sources / References
Recap
In the last post, I bootstrapped my cluster’s control plane, both the etcd cluster and Kubernetes components, following the tutorial in Kubernetes the Hard Way. In this post, I will bootstrap the worker nodes, but first, I need to fix a few issues.
A few details for reference:
- My hypervisor is named
nucklehead(it’s an Intel NUC) and is running FreeBSD 13.0-CURRENT - My home network, including the NUC, is in the 192.168.0.0/16 space
- The Kubernetes cluster will exist in the 10.0.0.0/8 block, which exists solely on my FreeBSD host.
- The controllers and workers are in the 10.10.0.0/16 block.
- The internal service network is in the 10.20.0.0./24 (changed from 10.50.0.0/24) block.
- The cluster pod network is in the 10.100.0.0/16 block.
- The cluster VMs are all in the
something.localdomain. - The
kubernetes.something.localendpoint forkube-apiserverhas the virtual IP address 10.50.0.1, which gets round-robin load-balanced across all three controllers byipfwon the hypervisor. - Yes, I am just hanging out in a root shell on the hypervisor.
Fixes
I Need This in a Larger Size
First off, the disks on the controllers filled up. The bulk of the usage came from etcd data in /var/lib/etcd. As I noted, I had only allocated 10Gb to each disk, because I don’t have an infinite amount of storage on the NUC. However, I still have enough space on the hypervisor’s disk to add space to each controller, especially because their virtual disks are ZFS clones of a snapshot base image. ZFS clones use copy-on-write (COW); they only consume disk space when a change is made on the cloned volume.
However, as I also noted, using ZFS volumes and CBSD makes it pretty easy to increase the size of the guest VM’s virtual disk.
- Stop the VM
- Use the
cbsd bhyve-dskcommand to resize the VM’s virtual disk - Run
gpartagainst the volume’s device to increase the size of the filesystem. Note this only works safely if it’s the last partition on the disk. We’re doing this from the hypervisor so we don’t have to re-write the partition table for the live VM, which would either involve booting a rescue CD (which I’m too lazy to figure out) or make the change from the live VM, which is a bit scary when modifying a mounted partition, but can be done. - Restart the VM
- Log in to the VM and run
resize2fson the resized partition.
I increase the virtual disk on all three controllers and everything is up and running again, except etcd on one controller won’t restart because of a corrupted data file. I read more docs and figure out I need to stop etcd, remove the bad member from the cluster, delete the contents of /var/lib/etcd, then re-add the member to the cluster. etcdctl will output several lines that need to be added to the errant member’s /etc/etcd/etcd.conf before restarting etcd on that host. (I forgot to grab the shell output.) etcd came up, joined the existing cluster, and started streaming the data snapshot from an existing member.
Except kube-apiserver keeps writing its own TLS certificate in /var/run/kubernetes and it keeps using only the primary IP address on the primary interface plus the gateway IP address in the SAN (Subject Alternative Name) list, while connections to etcd and other K8s controller services go over the loopback interface.
Space
I check the documentation, and as long as kube-apiserver has a certificate and key specified by the --tls-cert-file and --tls-private-key-file options passed at start time. They’re both present and correctly set in /etc/systemd/system/kube-apiserver.service, so I am comfused. I happen to be running ps on one of the controllers while checking the etcd cluster and the command’s arguments look odd. As in, they end with a trailing \. I look at /etc/systemd/system/kube-apiserver.service and sure enough, there’s a trailing space after the end-of-line continuation \ of the last argument passed to kube-apiserver at start. The ‘\ ’ would have been interpolated not as an end-of-line continuation, but as a string.
systemd supports a list of start commands, so it would have started kube-apiserver without error, throwing an error when it couldn’t run the trailing options as an actual command. But since the service process itself started without issue, I didn’t notice. Removing the trailing space from the file fixed the issue.
Now that these issues are taken care, the control plane hosts should be stable and reliable, at least for more than 24 hours.
Bootstrapping the Kubernetes Worker Nodes
Most of this section is straightforward, other than updating IP addresses and ranges.
When I created the worker VMs, I added, through some hackery of CBSD’s cloud-init data handling, a pod_cidr field to the instance metadata to configure each worker with its unique slice of the pod network. cloud-init puts the metadata in /run/cloud-init/instance-data.json. We need this value now to configure the CNI (Container Network Interface) plugin.
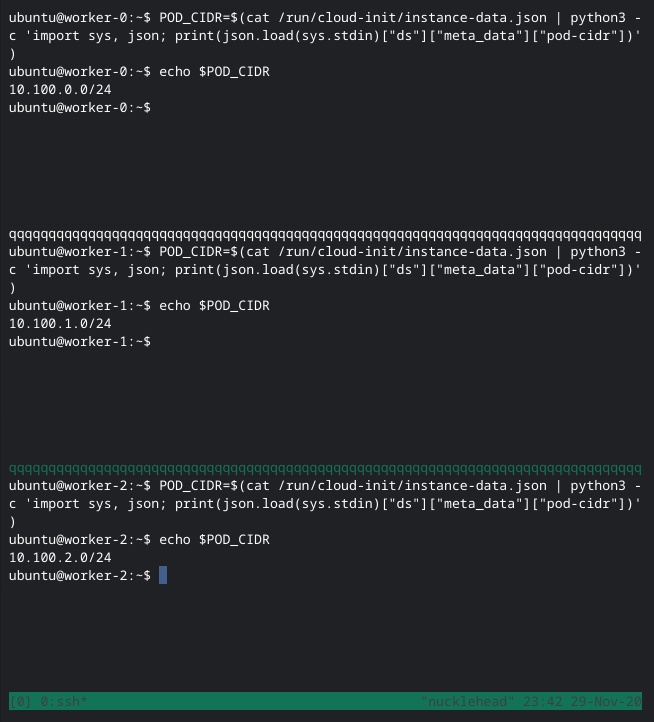
I still haven't found a better terminal type
After finishing the configuration, everything looks as expected.
Configuring kubectl for Remote Access
This section only requires setting the KUBERNETES_PUBLIC_ADDRESS variable to my VIP for the kube API endpoint.
Provisioning Pod Network Routes
This part gets a little more complicated. In the tutorial, it relies on the Google Compute Engine’s inter-VM networking and routing abilities. However, since all the inter-VM networking for this cluster goes through the FreeBSD bridge1 interface where ipfw is already doing all kinds of heavy-lifting, I can also use ipfw to handle the routing for the pod network.
Deploying the DNS Cluster Add-on
In this section, since my IP blocks differ, I had to download and edit the YAML for the DNS deployment.
At this point I end up massaging my cluster network a bit, changing the cluster network’s netmask from /8 to /16 and adding the alias 10.10.0.1 to the bridge interface on the FreeBSD hypervisor to put a gateway in the 10.10.0.0/16 VM network as it was no longer in the same CIDR block as the old gateway, 10.0.0.1.
Oddly, though, my cluster ended up assigning 10.0.0.1 to the cluster’s internal Kubernetes API proxy Service, even though that is outside the configured 10.50.0.0/24 Service network. I wonder if that happened because 10.50.0.1 was already a routable IP address within the cluster, as I had configured it as the external Kubernetes API endpoint and as a virtual IP on the controllers?
Either way, I need to move the “public” API endpoint address out of the services block. It’s arguably easier to change the service CIDR block for the existing cluster as it’s only set as arguments for kube-apiserver and kube-controller-manager. I will also need to update the kubernetes.pem used by kube-apiserver to add the new internal service IP address to the list of accepted servernames.
I was so focused on getting the updated certificate files copied around and restarting dependent services that I initially forgot to update the --service-cluster-ip-range option for kube-apiserver and kube-controller-manager. I’m not completely sure why the service was initially given the cluster IP 10.0.0.1, which I could have tested by deleting the kubernetes Service before making the changes, but I didn’t think of it until afterward. Once everything was updated, the service was recreated with the 10.20.0.1 address, as expected.
Smoke Test
Now it’s time to smoke test the cluster. The data encryption and deployment tests work fine without modification.
For the NodePort Service, I just need to connect directly to the worker IP from the hypervisor, because it has a direct route to the cluster network.
And that’s it!
This series of posts show one way you can run a Kubernetes cluster on FreeBSD using OS-level virtualization so we can create the traditional, supported Linux environment for Kubernetes. My next post will look at some potential alternatives in various stages of development and support.
Sources / References
- https://cloudinit.readthedocs.io/en/latest/topics/instancedata.html
- https://github.com/kelseyhightower/kubernetes-the-hard-way
- https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/
- https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#replacing-a-failed-etcd-member